
HR如何应用数据思维
(上集)
序:
在上一篇文章《HR的数据思维》里开了个头,谈到了数据思维和基本的应用范围,而如何将数据思维和数据挖掘、数据分析应用于更具体的HR六模块工作中,则是本篇文章将要谈到的内容——上一篇侧重于原则和基础,讲的是数据的意义以及数据对HR而言所带来的价值和作用;本篇侧重于策略和技术,讲的是如何采集和挖掘与HR六模块有关联的数据,并将数据进行编码编辑成信息Information,再将Information提炼为知识Knowledge,最后有些可以形成智慧Wise。但是篇幅所限,不会对所有模块或所有数据都进行深度挖掘和扩展,因为不想又写成系列文章,因为太耗费时间精力了,而我还要忙着业务开发与项目交付的事情,所以,请读者朋友们原谅!
正文:
一、将数据思维应用于HR管理领域的基本策略与注意事项:
上一篇谈到了数据思维能给HR带来哪些价值,但没有谈到应用数据思维以及做数据采集和数据挖掘时的基本策略与注意事项;实际上,尽管有非常多的数据可应用于HR管理领域,但还有许多数据都是无用数据或弱相关数据,甚至有些数据是干扰项,而这些无用数据与干扰项,是每一个HR必须回避甚至是弃之不用的。所以,HR们需要在采集数据、分析数据、挖掘数据之前,明确一些注意事项并掌握一些基本的策略。
总体上,有三个基本策略与五个注意事项需要掌握,其中,三个基本策略分别是:
基本策略一:分析问题的基本策略是明确目的性、完整性、相关性和时效性;
先说目的性。做任何分析都需要基于一个确定的前提:为了什么目的而展开分析?一个基本的常识是目的决定手段方法,如果没有明确的目的或者只是为了分析而分析,那么这样的分析将毫无意义,不过是将认知、了解事物的全貌扩大而已,但缺乏目标/目的的分析固然可以扩展分析对象的全貌,但必然会让视角过于宏大而没有边界、失去重心。因此,正确的起点是明确分析问题或事物的目的,然后根据目的来选择分析的维度与要素,其次才是选择分析工具及方法。
再说完整性。分析的目的决定了需要划定的分析所应涉及的维度与要素,是目的决定手段和边界范围,如果仅仅是为了某个特别明确的目的,那么分析所涉及的维度和要素相对就比较少。例如,想了解一个人的体型是否匀称,通常只需要了解TA的BMI指数,胸围、腰围和臀围即可,而不需要去了解TA的血压、血脂、血糖、血尿酸、心率;因此,对于分析判定体型是否匀称而言,BMI指数与三围就足够;其他的分析维度和要素,已经超出了体型匀称与否的范畴。
第三是相关性。如前所述,分析的维度与要素并非越多越好,涉及范围越大干扰项就越多而且会导致分析的难度和成本提高,如非十分必要则不必选择弱相关甚至是不相关的维度与要素。例如,招聘面试时,求职者的性取向、政治面貌和宗教信仰就属于不相关的维度,但对于某些特别的组织(如政府机构)和特别的职务(如军人、特工、医生),这些维度与要素就显得非常必要并且也与是否胜任是否匹配具有高度相关性。举个例子,面试官想要了解求职者相对完整的信息,而求职者的个人信息类型中,除了道德、法律等情况,最重要的是知识、技能、性格特质行为模式(素质,冰山模型的水面以下部分)以及求职者过往的业绩和履历;至于求职者的家庭情况、兴趣爱好、生活习惯,理论上与素质有关系,但毕竟是弱相关项所以就尽量不去询问(在美国,求职者与工作无关的个人信息如家庭、婚育、宗教信仰等不允许询问,否则涉嫌侵犯隐私或就业歧视,会被处以高额罚款甚至是入刑)。尽管国内尚未有相关立法,但在面试或给求职者做背景调查时务必注意规避此类可能存在的风险,此外,90后的自我意识和隐私意识比70后和80后高得多,此类与职位要求无关或弱相关的问题尽量别问,否则很可能会招致90后求职者的反感甚至是鄙视。
最后是时效性。相当多的数据与信息有时效性,并且有些时效性相当短。例如薪酬数据和岗位职责等信息,前者的时效性通常为一年,因此薪酬调查报告都是每年更新一次,而后者在互联网公司尤其是正在推进OD(组织发展)的公司,岗位设置和岗位职责的时效性通常还不到一年,原因也很简单:互联网公司开始重资产运营并加大业务的线下化,而传统行业则在开始轻资产运营的同时加速了业务的线上化,在业务模式调整和OD的进程中,势必会有大量的部门和职位面临重组,那么岗位名称与岗位职责的短平快调整也就再正常不过了。因此,分析问题和事物时需要特别注意时效性,否则过期的数据与信息只能让你作出错误的决策。
基本策略二:解读数据的三种方法有经验、专业知识、对标解读,可根据实际情况择其一或全选;
同样一张X光片或彩超,一个入行一两年的医生和从业十年的专家所给出的结论很可能会截然不同,原因绝不仅仅是经验和专业知识,还与对标有关(不同病患个体之间的差异)。
用经验来解读数据是最简单的方法,尽管此种方法并不科学也略显不严谨,但胜在对操作者的要求很简单,只需具备在相关领域的丰富经验即可胜任此项工作。但是,在具体操作时还不能只依赖经验,还需要充分考虑分析的问题与事物所处的外部环境,尤其是地缘——例如,大城市尤其一线城市的平均婚育年龄大,所以30岁还单身的女性在诸如北上广深这些一线城市就很常见,而在三四五线城市则相对较少;因此,同样是招聘30岁左右的女性员工,在一线城市和三四五线城市所需要考量的侧重点通常就不太一样。总之,在依靠经验来分析问题和事物时,需要充分考虑地缘的差异、人口结构和经济环境,因为这些变量将会直接影响到经验的适用性。
用专业知识来分析问题和事物也是最常用的方法,但需要建立健全应用时的标准——知识本身并不会告诉你用来分析问题与事物时应该采取何种标准,只是让你掌握一种理论与方法,这个标准还需要自己来建立;或者将涉及的知识范围和深度进行扩展,形成更深层次和更具针对性的知识,或者可以称之为knowhow,即隐性知识。例如血压升高,除了疾病导致的高血压之外,人在受到惊吓、愤怒、紧张时,血压也会升高。要判定血压高不高,不能只盯着血压计,还需要充分考虑测量时被测者的状态。
对标解读也是最常见的分析问题分析事物的方法。例如,去分析公司的年度离职率,只静态的看数据没有意义,跟不同行业的公司对比也没有意义,要对标只能找同业领先的公司做对标才有意义,此为横向对标。还有一种对标是内部对标,即对比不同时期的数据,从中找出规律、评估数据与指标是在好转亦或是恶化。例如,餐饮业的员工流动性很高,平均达到30%以上,远高于其他行业。但是,餐饮业的标杆海底捞,其离职率不足10%,堪称业界奇迹。这一数据甚至比许多工业企业和高科技公司都要低。重点在于,导致餐饮业高离职率的原因有很多,而之所以行业平均达到30%以上的离职率而海底捞不到10%的离职率,背后的原因就不那么简单了,既有薪酬福利因素,也有企业文化因素和基础管理的因素,还有海底捞的业态不同于传统中餐的业态因素(火锅业态的标准化程度明显高于其他业态的中餐)。
基本策略三:在应用数据思维之时勿忘形象思维。
数据思维的优点很突出,如客观、理性、易于比对,但缺点也同样明显,如生硬、不直观、对专业有较高要求。因此,在分析问题与事物时,最好同时选择数据思维+形象思维这两种方式。
以下图为例,同样一个人,用形象思维和数据思维来描述,给人的感受就不尽相同。
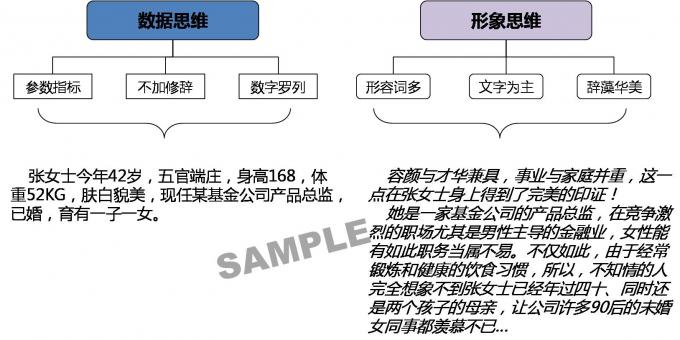
图一:数据思维与形象思维对比
数据思维的应用需要具备一定的知识积累和训练,是专业人员分析问题、解决问题的重要方式,虽理性客观但冰冷且不生动,所以并不适合那些未经训练的非专业人士;而形象思维则源自生活经验与阅历,更多源自常识,很直观、生动也易于理解,但会因个人经验与判断力和审美的差异导致认知不统一,但适合所有人以及绝大多数应用场景。
数据思维与形象思维不是非此即彼的关系而是互为补充的关系。对于受过训练的专业人士而言,在应用时通常都会两种思维方式并用,因为这对事物、对象与问题的理解会更全面、更立体。
说完了三个基本策略,接着再来聊聊四个注意事项。
注意事项一:完整的数据思维是DIGIT+TEXT,即数字+文本,缺一不可;
数字思维不是量化思维,而是DIGIT+TEXT即数字+文本的思维方式。只有解读带有文本、带有语义的数据才有意义,才是完整意义上的数据思维。其中,文本主要是指体现数据类型、属性、极性、强度的文字描述或文字概括,通常将此类文本称为指标,例如健康类(如血压、血脂、血糖)、经营类(如营业收入、净利润、人员数量)、管理类(如可靠率、合格率、误差率等),还有体现程度/等级的指标,如贷款五级分类里的正常、关注、次级、可疑、损失,并且,这五类文本其实都有相应的数字量化标准,而非定性标准。
在理解、描述和解决问题与事物时,文本与数据都不可或缺;只有文本则过于主观并且标准难以统一,只有数据则会有失偏颇且过于片面。
注意事项二:数据之间既有因果关系也有相关关系,而因果关系是重点;
舍恩伯格在其著作《大数据时代》里专门谈到过,数据之间并不只是因果关系(如A决定B,B决定C),更有相关关系(如A的出现与B的出现之间存在相关性),但严格意义上说,因果关系才是重点。但是,舍恩伯格在此书中所表达的观点并未对因果关系与相关关系进行展开,只是偷了个懒不去探寻为什么,只是说明是什么(当然这种懒也是必要的,因为不必对过多的数据进行因果关系的验证)。
从亚马逊的图书搜索推荐(当当也是跟亚马逊学的)到沃尔玛将蛋挞与飓风来临时的防灾用品放在一起销售的案列。在这些例子里,蛋挞与飓风用品一起购买的关联行为就是“是什么”,舍恩伯格认为没必要了解为什么飓风来了美国人喜欢吃蛋挞,所以他将飓风和蛋挞这两个风牛马不相及的事物用相关关系来定义。但如果认真研究你会发现,其实之所以购买哈耶克《通往奴役之路》的读者通常也会购买凯恩斯的《就业、利息和货币通论》,是因为购买《通往奴役之路》的读者,通常也会补充了解在古典自由主义和自由意志主义思想之外,社会主义思想的异同与成绩:做研究与学习通常都会比对一种以上的思想流派,从中获得碰撞的灵感与启示。而飓风一来蛋挞就卖得好,其实是因为需要高热量食物存储在家里以备断水断电的紧急情况下的人体每日所需的热量摄入。因此,从实质上看,世间万物之间绝大多数都是因果关系,而相关关系虽然存在但毕竟很少,但优点是研究相关关系的难度、周期和成本远比研究因果关系要低得多。
在大数据时代,在信息技术和云计算如此发达的今天,就算不是用于大数据分析而是“小数据”分析,也不能只看因果关系而忽略了相关关系。
注意事项三:不唯数据论、不只靠数据思维来认知、描述与解决问题;
判定一个人、一件事、一个物体好坏与否、适合与否,并不总是需要依赖数据,绝大多数时候人们都是通过生活常识和既有的道德准则和法律,或者是通过人类的本能。
例如,偷窃100元跟偷窃1000元都是偷窃,都是违法行为,我们不必去根据其偷窃的金额大小去判断行窃者是否违法;当我们感觉热了会脱掉衣服冷了会添加衣服,而不必用温度计测量环境温度;站在有护栏的楼顶天台时我们会感到害怕,而不必安慰自己说有围栏保护不必担心高空坠落。因为常识、经验、感觉、本能,都是我们简化后的判断方法和依据,而不必事事都依靠数据或指标。
注意事项四:充分意识到数据思维的局限性。
数据可以解释现象、阐明规律,但都是依托于历史数据;对于未来的趋势,虽然可以通过既有的数据,设计相应的算法进行预测,但不能忽视的基本前提是:外部环境、内部变量必须既定不变,否则基于历史数据和算法所得出的预测和判断极有可能是大错特错。
当前AI是个热点和风口,但应用还非常不成熟,例如你百度一种疾病,但搜索引擎可能推荐给你一堆莆田系医院的链接或者治疗肾虚阳痿的药物广告。而这背后,其实就是对数据的引用、对算法的构建存在大大的误区(或者是故意而为)。
上一篇文章《HR的数据思维》里谈到了IBM的知识管理模型,底层是DATA、之上是Information、再上是Knowledgez,最顶层是Wise。这四层从底层到顶层可以“进化”,也可以同时并存;如果缺乏data,那就用knowledge或wise来解决。经过挖掘和整理后的数据,可以形成信息;经过分类、编码和加工润色后的信息,能够形成知识;多样性和有深度的知识或经验,在一定程度上可以升华为智慧。数据、信息、知识与智慧这四者之间并不仅仅是递进关系,也可以是并行关系。总之,相信数据、挖掘数据、应用数据但不唯数据论!
后记:
社保新政有惊无险了一把,但如同“末日审判”只是延迟到来而不会消失;李总9月18日晚上的国常会议决议发布后,让数以百万级的中小微企业暂时松了口气,希望能够用时间换空间但出来混迟早都是要还的!
所以,从现在开始的往后不到2年时间内,诸多中小微企业的HR们的工作重心就是如何用低成本、更规范、更有成效的方式来做好HR工作,从而帮助业务部门解决问题、可持续发展——这个话题很大,能够做的事情也很多。杨老师有系统的方法和模式去帮助各位小伙伴们和小伙伴们的老板,具体内容我会在下期的文章里做一个说明文;或者,你可以聘请我当你的常年顾问,让我帮你提升自己、创造价值。
先剧透下:COE外包,将中小微企业不擅长或非核心的复杂工作交给外部机构或外部顾问,比如我,哈哈。
祝各位小伙伴工作顺利!







































 查看未读消息
查看未读消息 查看最新消息
查看最新消息




1楼 李晶Kingking
好文,手动点赞!
杨钢老师
@李晶Kingking:谢谢关注,有你们的捧场是我写下去的动力啊:)
李晶Kingking
必须支持,期待下集。