固定效应和随机效应的区别
在经济学、计量经济学和统计学中,固定效应和随机效应是两种常见的模型设定,用于处理异质性(heterogeneity)或特定个体特征对结果的影响。这两种方法的主要区别在于如何处理这种异质性。
固定效应模型假定所有个体的特定个体特征(如行业、地区、学校等)都是固定的,即它们不会随时间变化。这意味着在模型中,这些个体特征被视为常数项,并被包含在模型中。因此,固定效应模型假设个体特征对结果的影响是固定的,不会随时间变化。
与此相反,随机效应模型假定个体特征是随机的,即它们可能会随时间变化。这意味着在模型中,这些个体特征被视为误差项,并被随机分配给不同的个体。随机效应模型认为个体之间的差异是由误差项随时间的变动所导致的,因此对同一个误差项可以有多个个体观察到相同的影响,这些影响随时间的波动是随机化的。
固定效应模型更适合那些无法随机化个体特征的情形。此外,一些研究人员认为,将异质性因素包含在模型中能够更全面地估计误差项的影响。不过,随机效应模型更适合那些可以随机化个体特征的情形,因为它能够更好地控制个体之间的潜在偏误。
在选择固定效应还是随机效应时,需要考虑许多因素,包括数据集的性质、研究问题的性质以及研究者的假设等。一些研究者可能会倾向于使用固定效应模型,因为它更简单、更易于解释和估计。而另一些研究者可能会倾向于使用随机效应模型,因为它能够更好地控制潜在的偏误和不确定性。
总的来说,固定效应和随机效应是两种不同的模型设定,它们适用于不同的情形和目的。选择哪种方法取决于具体的研究问题、数据和假设。通过比较这两种方法的估计结果和置信区间,可以更好地理解它们在数据中的表现,从而做出更明智的决策。此外,在实际研究中,还需要考虑其他因素,如数据质量、模型选择偏误、过度简化等问题。因此,在选择固定效应或随机效应时,还需要结合实际情况进行权衡和分析。





















 查看未读消息
查看未读消息 查看最新消息
查看最新消息












 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问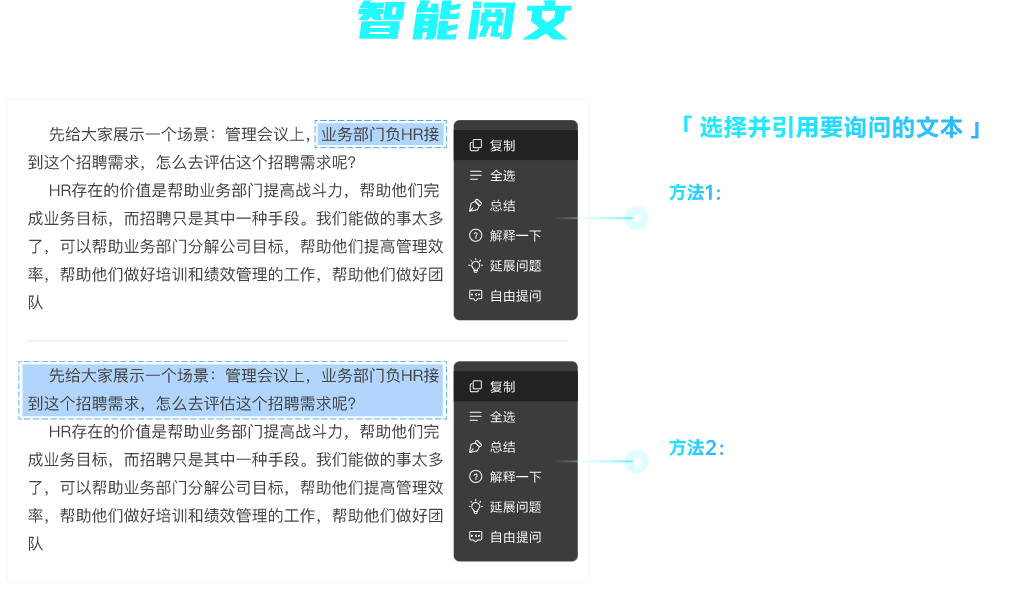












 复制
复制 分享
分享